- Published on
Karpathy 强推的 AI 知识库:用最简单的方式让 LLM 成为你的第二大脑
- Authors

- Name
- Milkli
- @Milkli24326
S 序言:Karpathy 的一条推文,和它引爆的涟漪
AI 大神 Andrej Karpathy 发了一条推文,分享他近期最常用的工作流——用 LLMs 为各种研究主题建立个人知识库。短短两天,千万级别播放。
"我最近发现一件非常有用的事:用 LLMs 为各种研究主题建立个人知识库。这样一来,我最近的大部分 token 使用量更多地用于处理内容,而不是编写或修改代码。"
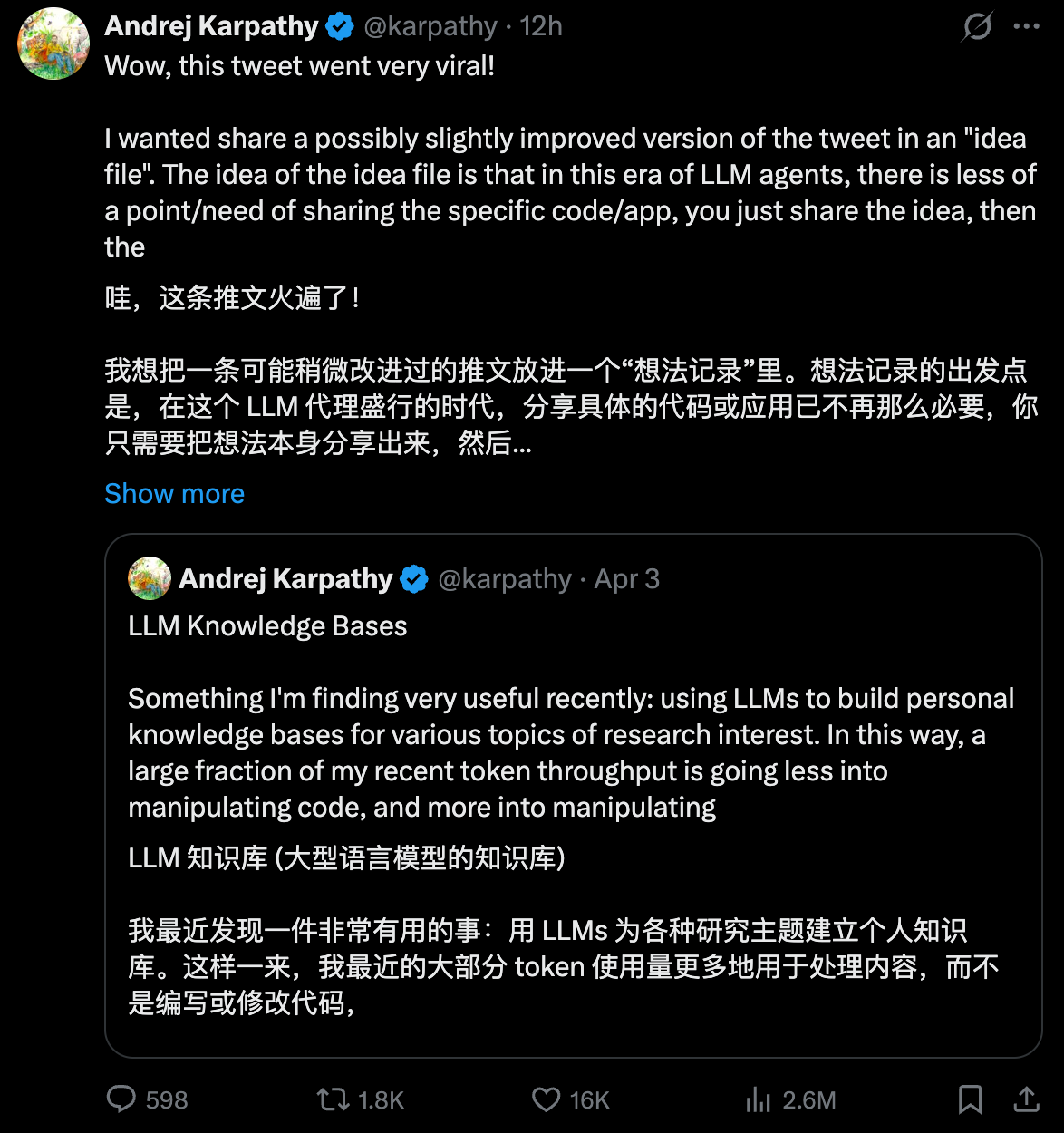
这句话击中了太多人。
我们都在用 AI,但 AI 不知道我们知道什么。你的笔记散落在 Obsidian、Notion、印象笔记、微信收藏夹里——每次问 AI 一个需要结合你个人知识的问题,它只能从模型自己的知识库里打捞,答非所问。

Karpathy 接下来放出了更具体的实现方案:三个文件夹 + 一个 schema 文件,不需要数据库,不需要特殊软件。这套方案究竟是什么?为什么说它代表了一种全新的 RAG 范式?
一、为什么你的"第二大脑"始终建不起来
大多数人对个人知识库的期待是这样的:把所有资料扔进去,需要时问一句,AI 给我准确的回答。
现实是这样的:导入几百篇笔记,建立复杂的标签体系,配好向量数据库,跑通 RAG pipeline——然后再也没有打开过。
知识库建了三次,废弃了三次。
问题出在哪?传统 RAG 的思路从根上就有缺陷——它把知识管理当成信息检索问题,而人积累知识的方式是不断迭代、关联、深化的,不是一锤子检索。
换句话说:传统 RAG 是一个搜索引擎。而你真正需要的是一个会生长的第二大脑。
二、LLMRAG 范式:LLM 不只是检索工具,而是知识管理者
LLMRAG(LLM-driven Personal Knowledge Base)核心转变只有一点:
传统 RAG:LLM 是答案的生产者。LLMRAG:LLM 是知识库的组织者和维护者。
具体来说,LLMRAG 的工作流包含五个关键环节:
1. 数据入口:零摩擦,让 raw/ 自己长出来
传统知识库第一个死的环节就是"导入"。打开文件夹,创建一个分类,开始复制粘贴——三天后热情消退,文件夹落灰。
LLMRAG 的设计哲学是:不要整理,什么都往里扔。
你只需要把看到的文章、笔记、截图、邮件、书签全部丢进 raw/ 目录。不用命名,不用分类,不用打标签。AI 的工作不是等你整理好了再来学习,而是从混乱的原材料里自己理出头绪。
这一步真正的加速器是自动化抓取工具。参考文章中博主 Nick Spisak 推荐的 agent-browser(Vercel Labs 出品,GitHub 26K+ 星)让 AI 可以直接操控 Chrome 浏览器抓取任意网页,一条命令把文章存入 raw/:
agent-browser open https://some-article-you-want.com
agent-browser get text "article"
这套组合拳解决了三个痛点:JavaScript 动态加载的页面、需要登录的内容、带交互式图表的研究论文。据 Nick Spisak 实测,agent-browser 相比 Playwright MCP 可节省大量 token(博主称省 82%,非权威 benchmark,仅供参考)。
核心原则:数据入口的摩擦力决定知识库的生死。让"扔进去"这件事无限简单。
2. 结构设计:Schema 即规则,AGENTS.md 是知识库的宪法
Karpathy 方案的精髓是什么?他说:
"我试图保持超级简单和扁平。它只是一个嵌套的 .md 文件目录。"
没有数据库,没有向量引擎,没有插件。但有一个 AGENTS.md(或 CLAUDE.md、README.md)——这个文件是整个知识库的"宪法",告诉 AI 三件事:
- 这是什么:你的知识库服务于哪个领域
- 怎么组织:
raw/放原始材料、wiki/放整理后的内容、outputs/放生成的答案 - 怎么更新:新素材进来时如何更新 wiki,主题之间如何关联
一个可复制的模板大概长这样:
# 知识库 raw
## 这是什么
一个关于 [你的主题] 的个人知识库。
## 快速开始
首先打开:[[wiki/INDEX.md]]
从这里开始导航和搜索你的知识库。
## 三种使用方式
### 1 浏览知识
打开 [[wiki/INDEX.md]]
↓
选择主题
↓
阅读文章
### 2 搜索知识
问题:告诉AI你想知道什么
↓
AI优先读[[wiki/INDEX.md]]理解结构
↓
搜索相关文章(Claude自动完成)
↓
综合答案存储到outputs/
### 3 添加新内容
新链接、笔记、文章
↓
保存到raw/
↓
Claude 自动编译为 wiki/articles/
↓
INDEX.md自动更新
## 文件结构
my-knowledge-base/
├── raw/ ← 原始数据,包含未处理的源材料。永远不要修改这些文件。
├── wiki/ ← 整理后的维基,完全由 AI 维护。
│ ├── INDEX.md ← 从这里开始
│ └── articles/ ← AI依据原始数据生成的文章
└── outputs/ ← 包含生成的报告、答案和分析。
## 维基规则
- 每个主题文章存储在 wiki/articles/ 中
- wiki/INDEX.md 列出每个主题及一行描述
- 每个维基文件以一段摘要开头
- 使用 [[articles/topic-name]] 格式链接相关主题
- 当添加新的原始源时,更新相关的维基文章
## 我的兴趣点
[列出 3-5 个你希望这个知识库关注的方向]
这就是整个知识库的设计。别小看这个简单的文本文件——它本质上是给 AI 的行为规范手册,决定 AI 怎么读、怎么写、怎么关联,彻底省掉了数据库设计的成本。
3. AI 编译:让模型把笔记编成网状 wiki
有了原材料(raw/)和规则手册(AGENTS.md),下一步是让 AI 做它最擅长的事:理解、总结、关联。
一条指令启动编译:
"读取
raw/中的所有内容,按照 AGENTS.md 中的规则在wiki/中编译一个维基。先创建 INDEX.md,然后为每个主要主题创建一个 .md 文件。链接相关主题。总结每个源。"
跑完之后,你会得到:
- 一个 INDEX.md——知识库的导航地图
- 若干 主题 .md 文件——每篇都有 AI 生成的摘要,并标注与其他主题的链接
- 原本散落在各处的零散笔记,被串成了网状结构
这里有一个反直觉的原则:人只读 wiki,不编辑 wiki。 维护是 AI 的工作,人的时间是用来提问和吸收洞见的。
4. 迭代正循环:越问越聪明
wiki 建立之后,下一步是什么?开始提问。
几个可以直接用的优质问题:
- "基于 wiki/ 中的内容,我对【主题】理解中最大的三个空白是什么?"
- "比较源 A 和源 B 对【概念】的说法,它们在哪里有分歧?"
- "仅使用这个知识库,给我写一份 500 字的【主题】简报。"
关键动作:把 AI 的回答存回知识库。
将 outputs/ 中的答案放入 outputs/ 目录,或让 AI 用新洞见更新相关的 wiki 文章。每一次问答都在扩充知识库,下一次答案质量必然更高——这就是 Karpathy 说的"越用越好用"的正循环。
5. 定期健康检查:消灭错误的复利
社区用户 @HFloyd 在 Karpathy 帖子下说了一句关键的话:
"当输出被归档回去时,错误也会复利。"
如果 AI 某次产生了轻微的幻觉并被存进 wiki,下一次基于 wiki 的回答会把错误进一步放大。
解法是定期运行 AI 健康检查:
"审查整个 wiki/ 目录。标记文章之间的矛盾。找出提到但从未解释的主题。列出没有 raw/ 源支持的声明。建议 3 篇能填补空白的新文章。"
每两周一次,AI 扫描 wiki 的逻辑一致性,揪出错误萌芽。这是知识库长期保持可信度的关键。
三、用 Obsidian + Claudian 搭一套完整的 LLMRAG
Karpathy 的方案是纯命令行的,适合开发者。如果你是知识管理爱好者,不想碰代码,Obsidian + Claudian 插件是最适合的桌面端落地方案——Obsidian 负责笔记管理和双链组织,Claudian 把 Claude Code 的 AI 能力无缝嵌入 vault。
第一步:安装 Obsidian,搭建知识库
- 打开官网下载桌面版:https://obsidian.md/
- 安装完成后,点击 创建知识库(Create Vault)
- 知识库名称填写
my-knowledge-base,存放位置随意(记住路径) - 创建完成,Obsidian 会打开一个空知识库
第二步:写入 AGENTS.md 宪法文件
在知识库根目录创建 AGENTS.md(即宪法文件),把上面的内容模板粘贴进来
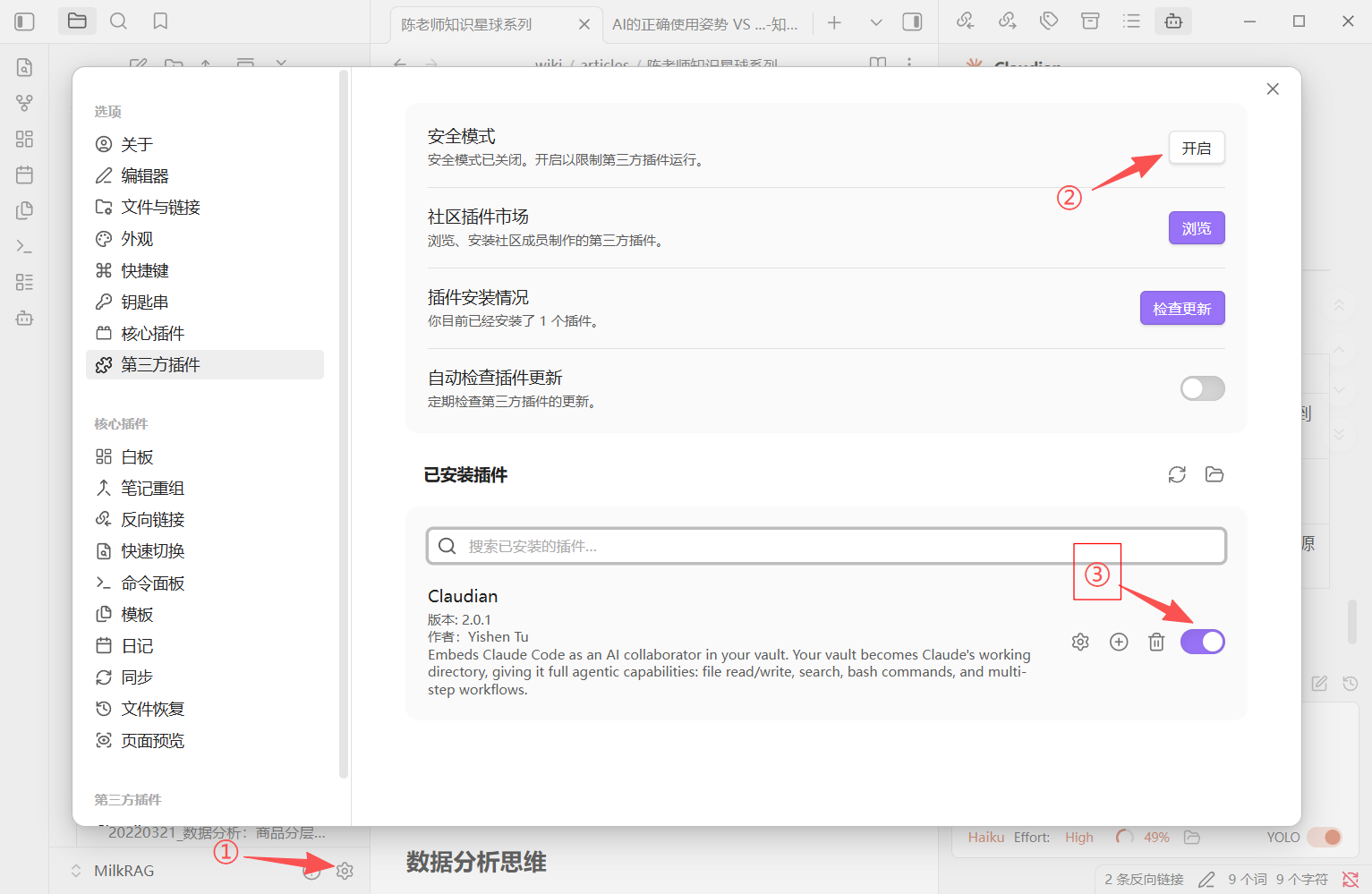
第三步:安装 Claudian 插件
方式一:社区插件市场(推荐)
- 在 Obsidian 中打开 设置 → 社区插件,关闭安全模式
- 点击 浏览,搜索
Claudian - 找到后安装并启用
方式二:GitHub 地址安装
如果你知道插件的 GitHub 地址,可以直接让 Claude 帮你安装。打开 Claude Code(或任意 AI 工具),发送以下 prompt:
本地路径有 my-knowledge-base 知识库,路径:E:\my-knowledge-base(替换为你实际路径),
帮我安装这个插件进去:https://github.com/YishenTu/claudian
Claudian 插件地址:https://github.com/YishenTu/claudian
安装插件前在Obsitian设置-第三方插件中关闭安全模式
第四步:用 Claudian 根据宪法搭建知识库结构
插件安装好后,在 Obsidian 底部工具栏找到 Claudian 图标(一只蚂蚁),点击打开对话窗口。输入以下指令:
读取 AGENTS.md 的内容,然后在 vault 中创建以下文件结构:
1. 创建 raw/ 文件夹
2. 创建 wiki/ 文件夹,并在其中创建 INDEX.md
3. 创建 outputs/ 文件夹
完成后告诉我结构是否正确创建。
Claudian 会自动在 vault 中创建好三个文件夹和 INDEX.md 索引文件。
第五步:导入素材,跑通第一次编译
- 把文章、笔记、截图全部丢进
raw/文件夹(不用整理!) - 再次向 Claudian 发送编译指令:
读取 raw/ 中的所有内容,按照 AGENTS.md 的规则在 wiki/ 中编译维基。
先更新 INDEX.md,然后为每个主要主题创建 .md 文件,链接相关主题,总结每个源材料。
- Claudian 会自动完成第一次编译,wiki/ 里就填充好了结构化内容
Obsidian Web Clipper 插件
Obsidian Web Clipper 是一款强大的浏览器扩展,它可以将网页内容快速保存到你的 Obsidian 知识库,搭配它能让你快速收录文章。
Obsidian Web Clipper 插件地址:https://obsidian.md/clipper
为什么推荐 Obsidian + Claudian 组合
| 工具 | 负责什么 | 为什么用它 |
|---|---|---|
| Obsidian | 笔记管理 + 双链网络 + 本地存储 | 完全离线可用,隐私零风险,vault 即知识库 |
| Claudian | AI 组织者 + 编译器 + 维护者 | 把 Claude Code 能力直接嵌入 Obsidian,不需要切换应用 |
| AGENTS.md | Schema / 宪法 | 告诉 AI 如何行为,是整个系统的灵魂 |
这与 Karpathy 的终端方案本质相同,只是把文件系统的操作替换成了Obsidian 的 GUI 操作。对于不熟悉命令行的用户,这套组合的学习曲线更低,上手即用。
四、范式对比:传统 RAG、LightRAG、GraphRAG vs LLMRAG
这一节说清楚一件事:LLMRAG 和其他 RAG 方案,解决的根本不是同一个问题。
| 方案 | LLM 的角色 | 核心机制 | 适用场景 | 致命弱点 |
|---|---|---|---|---|
| 传统 RAG | 检索 + 生成(两段分离) | Chunk 分块 → 向量检索 → Top-K 召回 → 生成 | 文档问答、客服 | 碎片化严重、关联性差、幻觉依旧 |
| LightRAG | 检索 + 生成(轻量化) | 简化向量索引 + 混合检索 | 超大知识库快速部署 | 本质仍是检索思维,无结构化能力 |
| GraphRAG | 检索增强(知识图谱加持) | 知识图谱嵌入 → 图遍历检索 → 生成 | 复杂关联分析、多跳问答 | 建图成本高,隐私敏感数据无法上云 |
| LLMRAG | 组织者 + 检索 + 生成(三位一体) | LLM 持续维护 wiki 结构,人只读不写 | 个人/团队知识管理 | 需要自动化 Agent 支持(但工具已成熟) |
传统 RAG 的原罪:检索与生成的割裂
传统 RAG 把"检索"和"生成"切成两段——先从海量 chunk 里捞出 Top-K 相似的文本块,再让 LLM 基于这些块生成答案。问题在于:
- 碎片化:每个 chunk 都是上下文的一家之言,AI 看不到知识之间的关联。
- 幻觉依旧:检索到的内容可能是偏的,LLM 照着错的文本"一本正经胡说八道"。
- 没有记忆:这次问答和下次问答毫无关系,LLM 不知道你上次知道了什么。
GraphRAG 的代价:美丽但昂贵
GraphRAG 用知识图谱重建了文档之间的关联,检索质量大幅提升,但它带来了新的问题:建图成本极高。将文档转化为知识图谱需要额外的 LLM 调用,抽取实体、关系,进行知识建模。维护一个实时更新的知识图谱,对个人用户来说几乎不可能。
另一个被忽视的风险:隐私。你的笔记、公司的内部文档,一旦进入知识图谱服务,就需要上传到云端。GraphRAG 方案大多面向企业场景,个人知识管理用 GraphRAG 是杀鸡用牛刀。
LLMRAG 的核心差异:循环 vs 单次
回到 Karpathy 的方案——它真正值钱的地方是什么?
不是检索,是维护。
LLMRAG 的 LLM 在整个生命周期中不断参与:抓取时理解内容、编译时建立关联、问答时产生洞见、归档时更新 wiki、下次检索时基于已整理的结构给出更精准的答案。这不是一次性的 RAG pipeline,而是持续运转的知识管理系统。
这也意味着:GraphRAG 和 LLMRAG 不是非此即彼的关系。GraphRAG 的检索能力可以作为 LLMRAG 的底层索引引擎——用图结构做检索,用 LLMRAG 做组织和维护,两者互补。但对于个人知识库来说,LLMRAG 的轻量方案已经足够。
五、写在最后:收藏不等于拥有
Karpathy 的帖子有 44K 人收藏。但收藏和真正用起来,中间差的是一个周末的动手时间。
这套系统的全部工具是:
- 一个文件夹结构(
raw/、wiki/、outputs/) - 一个 AGENTS.md schema 文件
- 一个浏览器抓取工具(agent-browser)
- 一个 AI 编码工具(Claude Code / Cursor)
没有数据库,没有向量引擎,没有复杂的 RAG pipeline。
扁平和简单才是个人知识库的正确答案。
从今天开始:
- 选一个主题
- 建好三个文件夹
- 把现有的笔记、剪藏、书签扔进
raw/ - 跑通 AI 编译流程
- 开始提问
剩下的交给 AI。越用越好用。
参考来源:
- Nick Spisak 教程:https://x.com/NickSpisak_/status/2040448463540830705
- Karpathy 推文(视频):https://x.com/karpathy/status/2039805659525644595
- Karpathy 推文(方案):https://x.com/karpathy/status/2040470801506541998