- Published on
2026 年 AI 编程 Agent 的真正分水岭,不是模型,而是 Harness
- Authors

- Name
- Milkli
- @Milkli24326
很多人看 AI 编程 Agent,第一反应还是那套老问题:
- GPT 更强还是 Claude 更强?
- Gemini 到底适不适合写代码?
- 新模型上线后,编程能力是不是又要洗牌?
这类讨论不能说错,但经常问偏了。
因为一个 Agent 在真实开发环境里失败,往往不是死在“不会想”,而是死在更低层、更机械、也更工程化的地方:它怎么读文件、怎么改文件、怎么验证结果、怎么处理错误、怎么恢复状态、怎么避免把一个小错滚成一场事故。
这也是为什么最近 “Harness” 这个词开始频繁出现。
但我不想直接重复一个流行结论——“Agent = Model + Harness”,然后把它包装成新的万能口号。问题没那么简单。真正值得问的是:
到底什么是 Harness?它为什么正在变成 AI 编程 Agent 的分水岭?更重要的是,哪些说法只是热闹,哪些才是本质?
先把问题问对:为什么“比较模型”这件事越来越不够用了?
一个常见误区是,把 Coding Agent 的表现几乎完全归因于模型本身。
这在聊天问答阶段勉强成立,但一旦进入软件交付场景,事情就变了。Agent 不只是“回答你”,而是要进入一条完整链路:
- 读代码与上下文
- 理解任务和约束
- 拆解行动步骤
- 调用工具
- 修改文件
- 跑测试或校验
- 根据结果自我纠偏
- 给出最终可交付结果
只要这条链路里有一环设计得差,模型再聪明,也会显得很蠢。
所以“哪个模型更强”当然重要,但它更像是在问发动机排量;而真实系统跑得好不好,还取决于变速箱、刹车、仪表盘、传感器、控制系统是不是靠谱。你不能一边给车装最强发动机,一边让它靠失灵的方向盘上高速,然后得出“这车不行”的结论。
这就是 Harness 真正切入的地方。
Harness 到底是什么?一句话版本太粗糙,得拆开看
先给一个工程化而不是营销化的定义:
Harness 不是某个插件,不是某个 Prompt 模板,也不是某个酷炫命令集合。Harness 是模型之外,所有用来约束、放大、纠偏、执行和验证模型能力的那套运行机制。
可以把它粗略拆成四类:
1. 输入层
决定模型看见什么、按什么结构看见。
比如:
- system prompt
- 工具 schema
- 文档注入方式
- 上下文裁剪与拼接
- 代码检索方式
- session memory
2. 执行层
决定模型“想到的动作”怎么变成系统里的真实动作。
比如:
- edit tool 的格式
- shell / sandbox 执行
- MCP / 外部工具接入
- 多 agent 协作调度
- 任务状态与 todo 管理
3. 反馈层
决定系统怎么发现错误、把错误喂回去,让 agent 修正。
比如:
- lint / typecheck / unit test
- 静态分析
- 代码评审 agent
- 浏览器验证
- 日志、指标、trace
4. 边界层
决定 agent 不能做什么,或者必须怎么做。
比如:
- 权限隔离
- 安全边界
- 人工审批
- 幂等控制
- 重试策略
- 回滚与恢复
换句话说,Harness 不是“外挂”,而是 Agent 的执行系统。
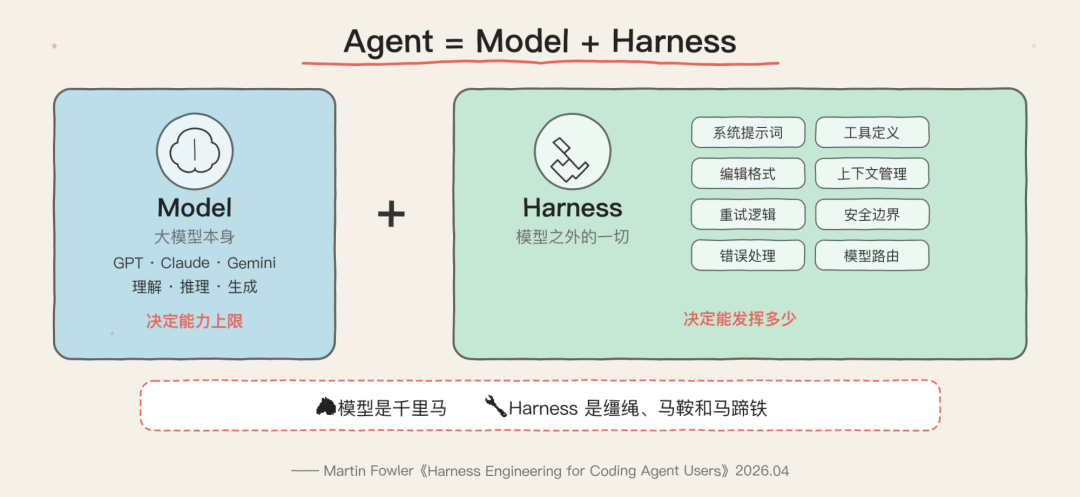
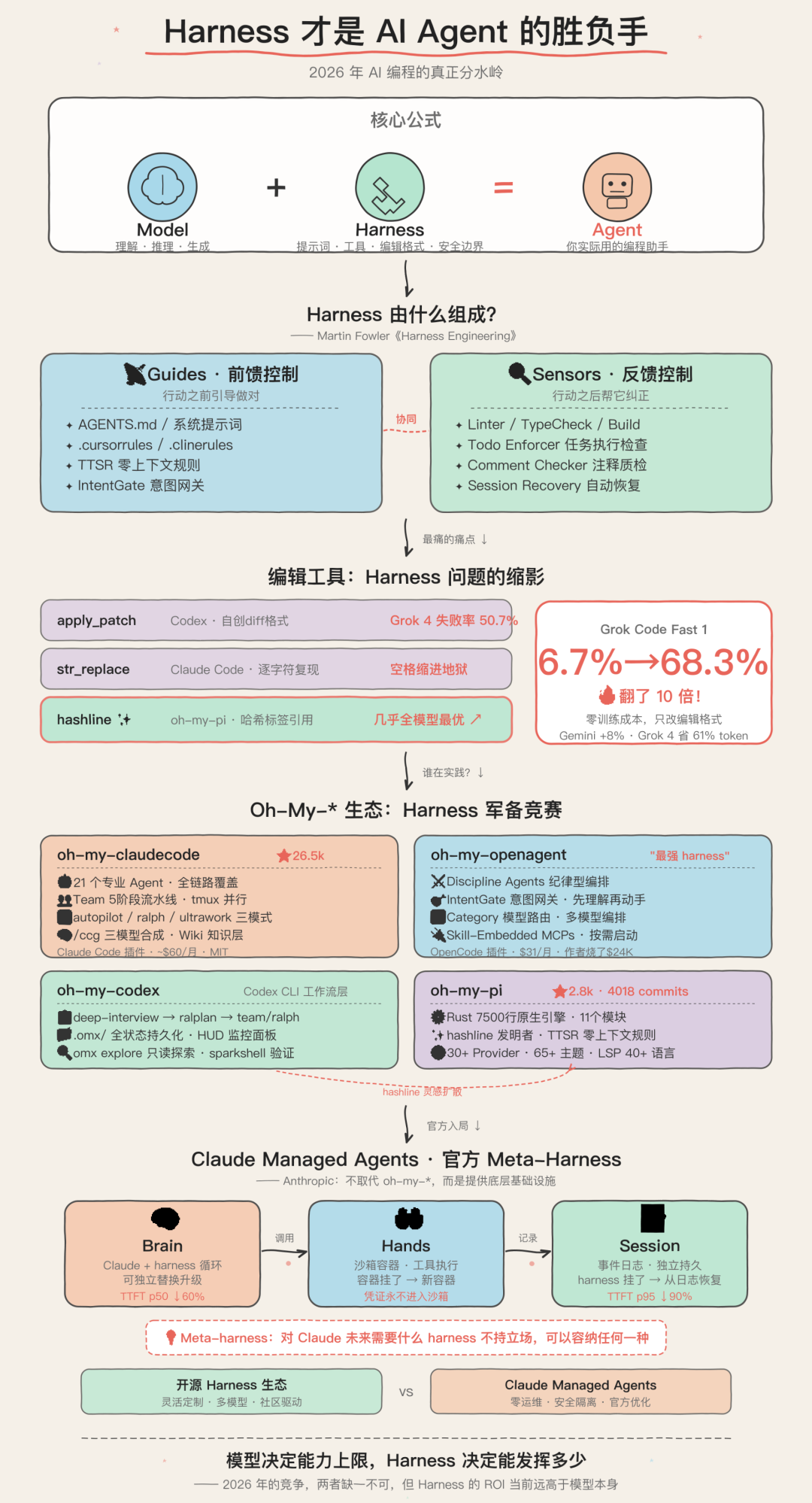
上面这张图把问题讲得很直白:Model 决定能力上限,Harness 决定这份能力到底能发挥出多少。这个说法我基本认同,但还要补一句:Harness 不只是放大器,它也是过滤器和减震器。
模型负责提出候选动作,Harness 决定这些动作会不会安全、稳定、可验证地落到系统里。
Martin Fowler 那套 Guides 和 Sensors,为什么值得重视?
这几年关于 Harness 的讨论里,我觉得最有价值的一点,不是某个具体工具,而是把 Harness 拆成了两个方向:
- Guides:前馈控制,尽量让 Agent 一开始就少犯错
- Sensors:反馈控制,出错后尽快发现并拉回
这个框架比“多写点 prompt”“多接几个 tool”高一个层级,因为它在问更本源的问题:
你是在赌模型第一次就做对,还是在设计一个允许它不断被校正的系统?
一个没有 Guides 的 Agent,容易从一开始就朝错方向飞。
一个没有 Sensors 的 Agent,就算错了也不知道自己错了。
而真实工程系统里,后者往往更致命。因为最可怕的不是失败,而是看起来成功的失败。
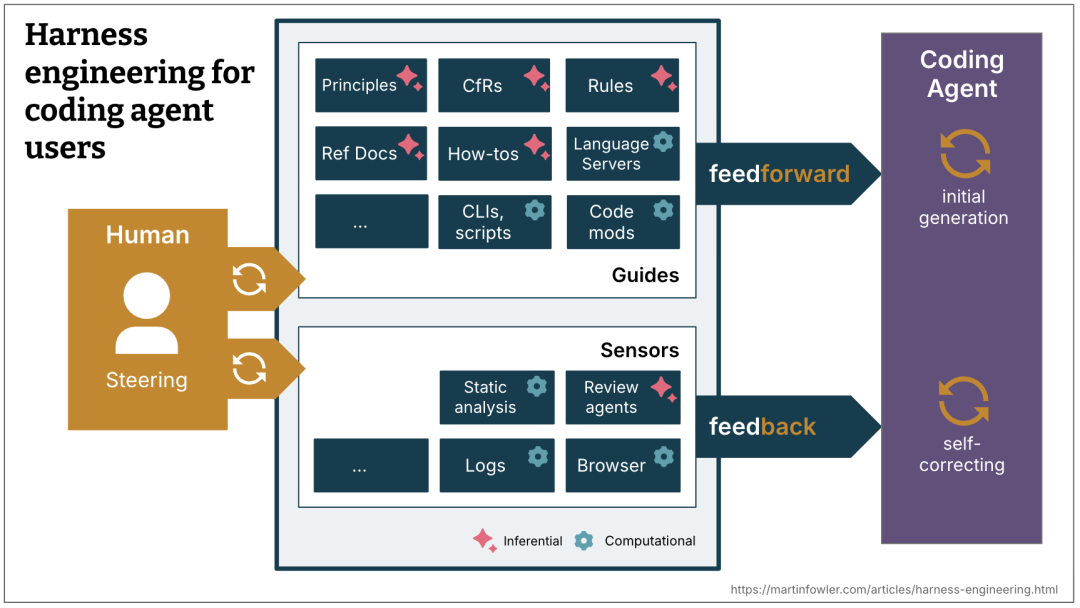
这张图很好地说明了人类在 Agent 时代该做什么:不是亲自替它写每一行代码,而是构建一套引导它、观察它、纠偏它的环境。人从“执行者”变成“系统设计者”和“监督者”。
这件事的隐含意义其实非常大:
如果你还在把 Coding Agent 当成一个更聪明的 autocomplete,你就已经落后了。真正的竞争点正在从“提示它”转向“驯服它”。
但别被口号带偏:不是所有性能提升都能直接证明 Harness 比模型更重要
原文里最抓眼球的部分,是编辑工具的对比实验。核心说法是:
apply_patch对很多非特定模型不友好str_replace极其脆弱,空格和缩进就能让它崩- 引入
hashline之后,一些模型的编辑成功率暴涨 - 例如 Grok Code Fast 1 从 6.7% 提升到 68.3%
这个案例说明了什么?说明 编辑格式这种看似细枝末节的设计,会强烈扭曲你对模型能力的观感。
但也要小心两种误读。
误读一:Hashline 一定是终极方案
未必。
它很可能在一类任务上显著更优,尤其是需要精确定位、避免 stale edit 的场景;但它不代表在所有模型、所有文件规模、所有工作流里都绝对统治。JetBrains 的 Diff-XYZ,以及 EDIT-Bench 这类编辑基准,本身也在提醒一件事:
编辑任务不是单一问题,没有一个格式天然适合一切。
误读二:只要 Harness 调好了,模型差异就不重要了
也不对。
Harness 再强,也无法凭空补出模型本不存在的能力。架构理解、复杂推理、跨文件重构、长链路规划,这些仍然受模型上限约束。更准确的说法应该是:
模型决定上限,Harness 决定你离这个上限还有多远。
如果一个模型本来有 80 分潜力,差 Harness 能把它打回 30 分;好 Harness 可能把它拉回 65 分甚至更高。
这很重要,但它不意味着 40 分模型能轻松变成 90 分模型。
为什么编辑工具会变成 Harness 争夺战的核心?
因为“改文件”这件事,是 Coding Agent 真正从认知走向执行的狭窄通道。
人类程序员看到一段代码,知道自己该改哪里,可以直接打开 IDE 动手改。
但模型不一样。它需要先:
- 在文本里定位目标
- 用某种格式表达修改意图
- 让外部系统正确理解它的意图
- 保证修改时上下文没过期
- 在失败后得到可恢复的反馈
这个过程一旦格式设计不合理,Agent 就会出现一种很典型的假失败:
- 它理解问题了
- 也知道要改哪
- 但它没法可靠地把“改哪”和“怎么改”表达给执行器
- 最后看起来像“不会写代码”
其实它不是不会写。
它是不会把修改安全地落盘。

从系统角度看,Hashline 这类方案真正解决的,不是“让模型更聪明”,而是把“修改定位”这件事从模糊自然语言,变成了更接近引用系统、坐标系统、乐观锁系统的东西。
这就是为什么它值得认真看待。
因为它碰到的是一个第一性问题:
Agent 最怕的,不是不知道改什么,而是知道改什么却无法稳定地把这个意图投递到代码库。
真正值得学的不是某个工具,而是它背后的设计原则
如果把 Hashline、各种 edit tool、以及近期很多 Agent framework 的实践抽象一下,会发现它们背后其实都指向几条共同原则。
原则一:让模型尽量少依赖“完美复述”
凡是要求模型精确复述长文本、空格、缩进、上下文片段的设计,都天然脆弱。
原则二:让执行动作具备可验证锚点
行号、哈希、结构化引用、AST 节点,这些都比模糊的自然语言定位更可靠。
原则三:让错误具备可恢复性
最糟糕的报错是“失败了”。
更好的报错是“失败了,因为第 42 行的锚点已失效,请重新读取后重试”。
原则四:把系统状态从隐式改成显式
todo、阶段、事件、上下文快照、恢复点,这些不该全靠模型自己“记住”。
原则五:不要把反馈当附属品
测试、审查、lint、浏览器验证,不是收尾动作,而是 Agent 系统的一部分。
这些原则一旦成立,Harness 就不再只是“贴心辅助”,而是决定系统可工业化程度的核心结构。
那些 oh-my-* 项目为什么会突然火起来?表面是生态,实质是 Harness 层内卷
最近很多项目名字都长得像:
- oh-my-claudecode
- oh-my-openagent
- oh-my-codex
- oh-my-pi
如果只看表面,你会觉得这是一波插件文化复兴:大家在给不同 Agent CLI 造“增强包”。
但如果往深了看,这波热潮真正说明的是另一件事:
市场已经开始默认:裸模型 + 裸 CLI,不够用了。
这些项目在拼的不是谁有更炫的指令,而是谁能更好地解决这些问题:
- 任务怎么拆
- 多 agent 怎么协作
- 工具怎么路由
- 出错怎么恢复
- 上下文怎么隔离
- 中间态怎么存
- 怎么避免把 token 烧在无效循环里
- 怎么让不同模型各司其职
这本质上都是 Harness 问题。
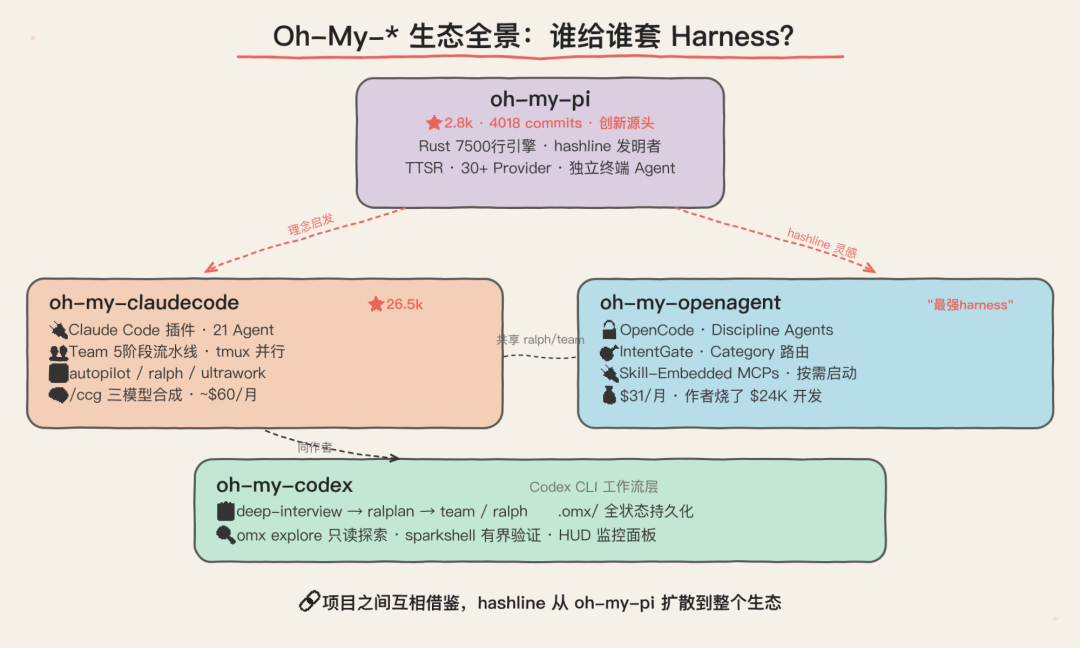
所以我对这波生态的判断是:
- 长期价值:有,而且不小
- 短期泡沫:也有,而且不低
因为很多项目现在仍在“好玩”“炫”“demo 感很强”的阶段。真正能沉淀下来的,不会是命令数量最多的那个,而是失败率最低、恢复能力最强、可持续维护成本最低的那个。
比起“Agent 更像人”,我更在意它是不是更像一个系统
这是我看这轮 Harness 讨论最核心的感受。
很多人描述 Agent 的时候,喜欢强调它越来越像人类程序员,会规划、会调试、会协作、会反思。这个方向没错,但容易让人忽视另一件更重要的事:
成熟的 Coding Agent,最终长得不像一个“聪明的人”,而更像一个“受控的系统”。
它应该有:
- 明确的输入契约
- 稳定的中间状态
- 可观察的执行过程
- 可恢复的失败机制
- 可迭代的反馈闭环
- 可插拔的工具接口
这张图就很典型。Harness 不再是边缘角色,而是连接 Session、Tools、Sandbox、Orchestration 的中心枢纽。
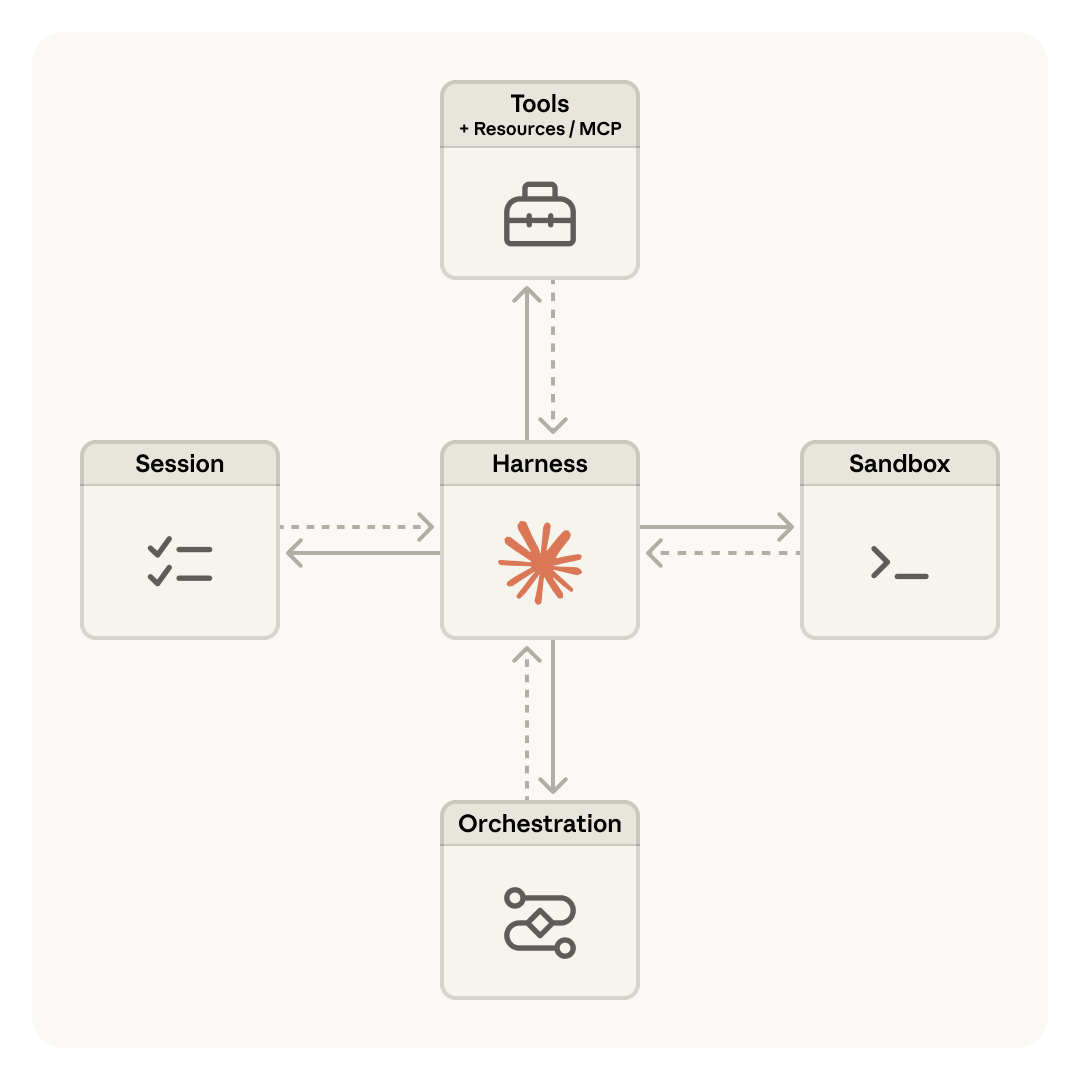
而另一张图则更进一步,把 Harness 放进了更抽象的模块化系统中:Session、Orchestration、Harness、Sandbox、Resources、Tools 都是可替换、可组合的组件。

这说明行业正在发生一个很重要的转向:
大家不再只是“给模型加能力”,而是在重新发明一层面向智能执行的运行时基础设施。
这才是真正的大分水岭。
所以 2026 年的真正问题不是“哪个模型最好”,而是“你有没有一套能让模型不白白犯蠢的系统”
说得更直接一点:
今天很多团队做 Agent,最大的问题根本不是模型不够强,而是系统把模型的能力浪费掉了。
浪费在哪里?
- 浪费在脆弱的 edit format
- 浪费在混乱的上下文
- 浪费在缺失的反馈回路
- 浪费在不可恢复的错误处理
- 浪费在不透明的状态管理
- 浪费在对“看起来成功”缺乏警惕
这也是为什么我会把 Harness 看成 2026 年 AI 编程 Agent 的真正分水岭。不是因为它替代了模型,而是因为它开始决定:
一个模型的真实能力,究竟能被兑现多少。
最后的判断:Harness 不是新概念包装,而是 AI 编程进入工程期的标志
如果只是停留在“Prompt 怎么写更好”,那还是技巧期。
如果开始系统化地讨论:
- Guides 和 Sensors
- Edit tool 和执行接口
- 状态管理和任务恢复
- Tool routing 和多 agent 协作
- 反馈闭环和安全边界
那就说明这个领域正在进入真正的工程期。
所以我对这件事的最终判断是:
第一,Harness 的重要性不是被夸大了,而是此前长期被低估了
过去大家把太多注意力放在模型排行榜,忽略了系统设计的杠杆。
第二,原文的结论方向大体成立,但个别数字不该被神化
像 6.7% 到 68.3% 这种结果非常有启发性,但不能直接拿来替代普适规律。工程世界最怕拿一个强案例当万能定律。
第三,真正值得学习的不是某个名词,而是背后的系统观
你可以不用 Hashline,也可以不用某个具体框架,但你绕不过这些根问题:
- 如何稳定修改
- 如何验证结果
- 如何暴露错误
- 如何恢复状态
- 如何持续演化
如果这些问题没解掉,换再强的模型,也只是把失败做得更昂贵。
如果这些问题逐步被解掉,那么 AI 编程 Agent 才会从“看起来很聪明的 demo”,真正变成“可进入生产系统的工程能力”。
这才是我理解的,2026 年 AI 编程 Agent 的真正分水岭。